









В России обучили нейросеть читать хрупкие свитки, не раскрывая их
. Это поможет сохранить раритеты и снизить риски их поврежденияВ России научили ИИ извлекать содержимое старинных свитков, не разворачивая их

Для обучения нейросети создали массив данных, включающий шесть образцов свернутых разными способами документов
Читать хрупкие свитки и книги нажатием одной кнопки, не раскрывая их, — такому умению обучили искусственный интеллект (ИИ) российские ученые, об этом компания-разработчик Smart Engines сообщила РБК Life.
Как заявляется, первая полностью автоматическая система виртуального развертывания свитков, не требующая вмешательства человека, поможет сохранить ценные старинные источники и снизить риски их повреждения.
Российские исследователи применили неразрушающий метод рентгеновской томографии и алгоритмы машинного зрения. Объект, который нельзя разворачивать, помещается в томограф. Затем реконструируется цифровая копия документа, над которой и производятся все дальнейшие манипуляции.
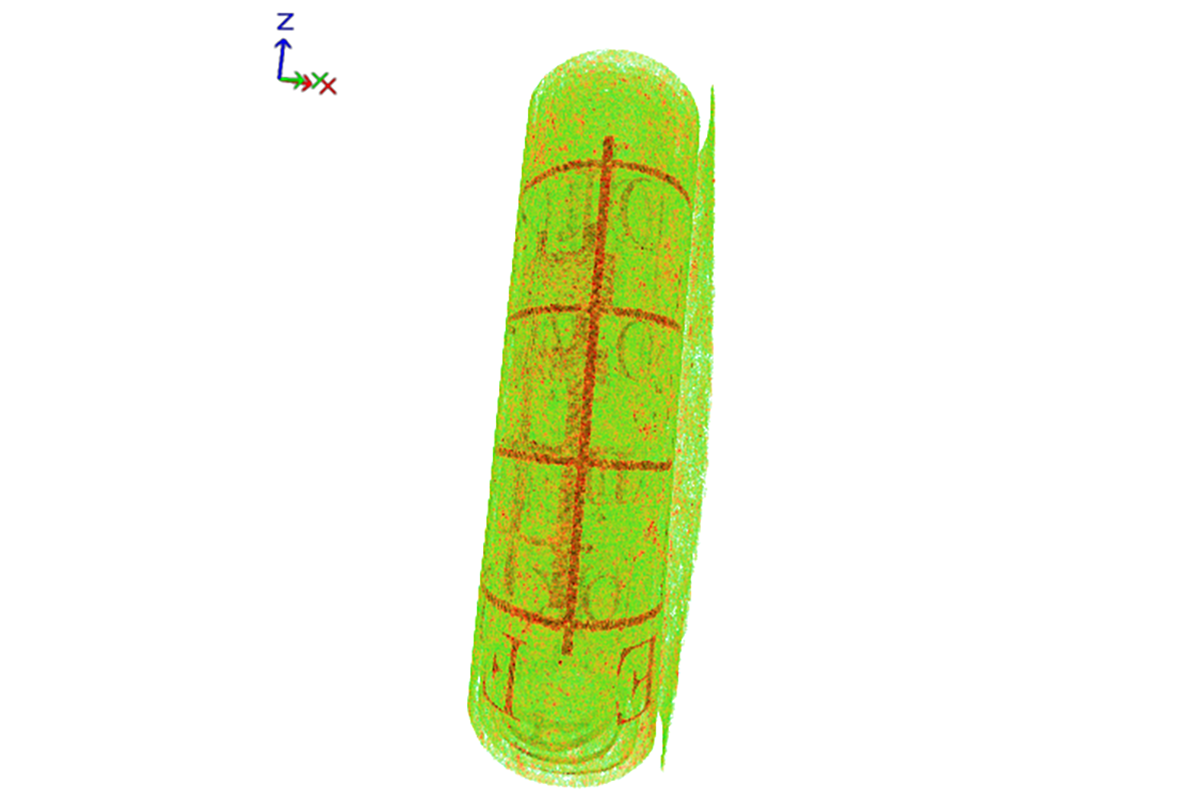
Томографическая реконструкция свитка
«Проблему анализа старых свитков с привлечением томографии ученые по всему миру пытаются решить более 20 лет, предлагая разные подходы с машинным обучением. Вопрос полной автоматизации процесса при этом до настоящего времени открыт. Обычно сначала нужно подобрать параметры, чтобы запустить работу алгоритмов, — это требует немало времени и сил. Затем алгоритмы могут отработать неправильно, если, скажем, слои документа слиплись, и человеку снова придется вмешаться», — пояснили РБК Life в компании.
Новый проект разработчики представили совместно с экспертами Федерального исследовательского центра «Информатика и управление» Российской академии наук (ФИЦ ИУ РАН). Искусственный интеллект извлекает и восстанавливает содержимое хрупких манускриптов, ему подвластно получение данных из бумажных, берестяных и серебряных свитков, печатных книг, которые пострадали вследствие естественного старения, воздействия влажности или пожаров и хранятся в особых условиях.

Фотография берестяной грамоты № 155, хранящейся в Государственном историческом музее, Москва
Ученые Smart Engines создали массив данных, включающий шесть образцов свернутых разными способами документов. На них нанесли буквы и цифры разного размера и схемы с различными графическими элементами. Этот своеобразный тренажер затем использовали для обучения новой нейросети.

На образцы свитков для обучения ИИ нанесли буквы и цифры разного размера и схемы с различными графическими элементами
Как рассчитывают авторы проекта, разработка «позволит сделать шаг на пути исследования и сохранения культурного наследия и откроет новые возможности для историков, археологов и других специалистов в области гуманитарных наук». Гендиректор Smart Engines, доктор технических наук Владимир Арлазаров пояснил, что результаты работы будут представлены российскими учеными в августе 2024 года на The International Conference on Document Analysis and Recognition (ICDAR) — ведущей международной научной конференции в области анализа и распознавания документов, которая состоится в греческих Афинах.

Ранее стало известно, что с помощью искусственного интеллекта удалось расшифровать более 2 тыс. знаков на старинных свитках, серьезно пострадавших во время извержения Везувия в 79 году н.э. Достижение принадлежит команде студентов-программистов из Германии, США и Швейцарии. Они несколько месяцев вели работу по изучению старинного артефакта и получили приз в размере $700 тыс. от инициаторов конкурса Vesuvius Challenge. Участникам предлагалось расшифровать текст свитка, использовав для этого изображение, сделанное с помощью компьютерной томографии. До наших дней после извержения сохранилось лишь несколько обугленных папирусов, над расшифровкой которых не первый год работают специалисты из разных стран.









